ВШЭ
Хранение и получение данных: что управленцу нужно понимать до разговора с IT
Расширенное сопровождение к лекции в ВШЭ о типах данных, СУБД, архитектурах хранения и роли данных в современном бизнесе
Так получилось, что в прошлом году я читал онлайн-лекцию в ВШЭ на тему «Хранение и получение данных». Это был в целом первый опыт так еще и для нетипичных для меня слушателей, так как это были не коллеги разработчики/архитекторов/дата-инженеров, а руководители разных функций крупных компаний.
То есть на людей, которые каждый день принимают решения, отвечают за процессы, бюджеты, команды, показатели, риски и развитие бизнеса, но при этом не обязаны знать, как писать SQL-запросы, настраивать шардирование базы данных или проектировать распределённое хранилище.
Именно поэтому задача была не в том, чтобы за три часа превратить управленцев в инженеров. Это невозможно, да и не нужно.
Задача была другая: объяснить, как устроен мир данных на уровне, достаточном для осознанного управленческого разговора.
Не на уровне «ой, это всё IT, пусть они сами разберутся». И не на уровне «давайте срочно внедрим AI, потому что все внедряют». А где-то посередине: чтобы руководитель понимал, какие данные есть в компании, откуда они берутся, куда текут, почему отчёты расходятся, зачем нужны хранилища, почему одна база данных не решает все задачи и почему искусственный интеллект без нормальных данных превращается в дорогую игрушку.
Эта статья — расширенное сопровождение к той лекции.
Для кого эта статья — руководители, аналитики и продуктовые лидеры, которые хотят говорить с инженерами и архитекторами на одном языке. Не нужно знать SQL, достаточно понимать, какие данные есть, откуда они берутся и почему это важно для бизнеса.
Коротко
- Данные — это актив, а не побочный продукт. Без владельцев, стандартов и качества они превращаются в шум.
- Универсальной базы данных не существует. SQL, NoSQL, колоночные, графовые, векторные — каждый тип решает свой класс задач.
- OLTP и OLAP нужно разделять. Касса и аналитический отдел — разные сущности, и их базы тоже.
- Архитектура важнее инструмента. Путь данных от источника до решения — вот что определяет ценность.
- AI начинается с данных. Без чистых данных, каталогов и управления доступом LLM лишь ускорит хаос.
- Импортозамещение — стратегический проект, а не разовая закупка. Нужен анализ нагрузки, совместимости и рисков.
Данные — это актив, а не инфраструктура

Давайте начнём с фразы, которую слышали почти все:
Data is the new oil. Данные — это новая нефть.
Эту фразу обычно приписывают Клайву Хамби. Её повторяли так часто, что она уже успела немного надоесть. Но проблема не во фразе. Проблема в том, что многие компании произносят её вслух, но продолжают относиться к данным как к чему-то второстепенному.
Как к побочному продукту работы систем.
- Где-то в CRM лежат клиенты.
- Где-то в ERP — закупки и склад.
- Где-то в 1С — бухгалтерия.
- Где-то в Excel — «самая правильная версия отчёта».
- Где-то в почте — договорённости.
- Где-то в голове у руководителя отдела — настоящая логика расчёта KPI.
Формально данные есть. Фактически ими никто не управляет.
И вот здесь важно зафиксировать простую мысль:
Данные сами по себе ничего не стоят, если с ними нельзя работать.
Нефть тоже не особенно полезна, если она просто лежит под землёй. Её нужно найти, добыть, очистить, транспортировать, переработать и превратить во что-то полезное. С данными примерно так же.
Если их просто хранить, они не дают бизнес-эффекта.
- Если в них бардак, они вредят.
- Если они противоречат друг другу, им перестают доверять.
- Если непонятно, кто за них отвечает, они быстро превращаются в цифровой мусор.
Поэтому правильнее говорить не «у нас есть данные», а задавать более неприятные вопросы:
- Кто отвечает за эти данные?
- Кто понимает их смысл?
- Кто следит за качеством?
- Кто определяет, какие данные важны?
- Кто может объяснить, почему в двух отчётах разные цифры?
- Кто принимает решение, какие данные нужно начать собирать уже сейчас, чтобы через год не было поздно?
Если ответ — «никто», значит данные никому не принадлежат.
А дальше цепочка короткая:
- Если нет владельца, то нет ответственности.
- Если нет ответственности, нет качества.
- Если нет качества, нет доверия.
- Если нет доверия, данные перестают быть активом.
Они становятся шумом.
Вопросы управленцу
- Какие данные в вашей зоне ответственности считаются критичными?
- У каждого такого набора данных есть владелец?
- Кто может объяснить расхождения в отчётах без ручного расследования?
Почему управленцу нужно в этом разбираться
Управленец, который не понимает принципов работы с данными, похож на водителя, который не знает, где взять топливо, куда его залить и зачем оно вообще нужно.
При этом от него всё равно ждут, что машина поедет.
Важно не путать роли. Руководителю не нужно становиться дата-инженером. Ему не нужно руками писать пайплайны, выбирать индексы в PostgreSQL или спорить о плюсах и минусах Kafka.
Но ему нужно понимать базовую механику:
- как данные появляются;
- где они хранятся;
- почему они портятся;
- почему отчёты расходятся;
- чем операционная база отличается от аналитической;
- почему «собрать всё в одну базу» — не стратегия;
- какие вопросы нужно задавать IT, аналитикам и владельцам процессов.
Это не техническая роскошь. Это управленческая необходимость.
Потому что сегодня почти любое серьёзное бизнес-решение так или иначе опирается на данные:
- запуск нового продукта;
- оптимизация запасов;
- оценка эффективности команды;
- управление клиентским опытом;
- автоматизация процесса;
- внедрение AI;
- переход на отечественное ПО;
- снижение операционных расходов;
- поиск точек роста.
Если данные плохие, то и решения будут плохими. Только выглядеть они будут убедительно, потому что их можно будет красиво показать на дашборде.
Красивый график не делает данные правильными.
Как выглядит работа с данными «по старинке»
В компаниях, где нет системного подхода к данным, проблемы обычно повторяются. Меняются отрасли, масштабы, названия систем, но симптомы очень похожи.
Первый симптом — расхождения в отчётности.
Финансы показывают одну цифру. Продажи — другую. Операционный блок — третью. Потом начинается ручная сверка, созвоны, пересылка Excel-файлов, уточнение формул, поиск «правильной версии».
Второй симптом — дублирование справочников.
Один и тот же клиент в разных системах может называться по-разному. Где-то «ООО Ромашка», где-то «Ромашка ООО», где-то запись привязана к ИНН, где-то к внутреннему идентификатору, а где-то вообще к фамилии менеджера.
Пока нет единой логики идентификации, компания не видит реальную картину. Она видит набор фрагментов.
Третий симптом — решения на основе догадок.
Когда нет доверия к данным, руководители возвращаются к интуиции. Интуиция важна, но она не должна заменять фактуру. Особенно в крупной компании, где масштаб ошибок становится очень дорогим.
Четвёртый симптом — дороговизна внедрения современных решений.
Компания хочет BI, предиктивную аналитику, персонализацию, AI-ассистента, автоматическую обработку обращений. Но быстро выясняется, что данные разбросаны, плохо описаны, не очищены, не связаны и юридически не всегда понятно, кто имеет право их использовать.
В итоге современное решение можно внедрить только после долгой и болезненной подготовки. А иногда оказывается, что сначала нужно не AI внедрять, а справочники привести в порядок.
Пятый симптом — долгий поиск информации.
Люди тратят часы и дни не на анализ, а на подготовку данных. Найти файл. Проверить актуальность. Спросить у коллеги. Сверить формулу. Пересобрать таблицу. Уточнить, почему вчера было одно значение, а сегодня другое.
Это невидимая стоимость хаоса.
Мифы, которые мешают компаниям работать с данными

Есть несколько устойчивых мифов, из-за которых компании годами откладывают нормальную работу с данными.
Миф 1. «Это сложно, дорого и долго»
Иногда действительно сложно. Иногда дорого. Иногда долго.
Но ошибка в том, что многие представляют работу с данными как огромный проект, где нужно сразу внедрить DWH, Data Lake, Data Mesh, машинное обучение, каталог данных, governance, MDM и ещё сверху корпоративного AI-ассистента.
На практике начинать можно сильно проще.
Например:
- описать ключевые источники данных;
- понять, какие отчёты собираются вручную;
- выделить критичные справочники;
- назначить владельцев данных;
- автоматизировать 2–3 отчёта, которые каждый день съедают время;
- согласовать единые определения ключевых метрик.
Это уже работа с данными. И она уже даёт эффект.
Миф 2. «Это задача IT»
Это один из самых опасных мифов.
-
IT может построить инфраструктуру.
-
IT может настроить интеграции.
-
IT может обеспечить хранение, доступность, безопасность и производительность.
-
Но IT не всегда знает, что именно означает показатель «активный клиент».
-
IT не должно самостоятельно решать, какие данные важны для коммерческого блока.
-
IT не может без бизнеса определить, какая логика расчёта KPI правильная.
-
IT не обязано угадывать, какие данные понадобятся руководителю через полгода.
Если данные — это актив, то бизнес не может полностью делегировать ответственность за них технической функции.
Правильная модель выглядит иначе:
- бизнес определяет смысл и ценность;
- аналитики помогают интерпретировать и моделировать;
- IT обеспечивает технологическую реализацию;
- управленцы создают культуру использования данных.
Вопросы управленцу
- Какие метрики в вашей функции считаются ключевыми?
- Кто утверждает их определения?
- Что сейчас приходится сверять вручную перед важным решением?
Миф 3. «У нас всё уже есть»
Обычно под этим подразумевается: «У нас есть BI», «У нас есть CRM», «У нас есть база», «У нас есть отчёты».
Но наличие инструмента не означает зрелость работы с данными.
BI может быть установлен, но показатели в отделах всё равно считаются по-разному. CRM может использоваться, но менеджеры всё равно ведут «свои таблички». DWH может существовать, но никто не доверяет данным. Отчёты могут быть автоматизированы, но бизнес-логика в них устарела.
«У нас всё уже есть» — опасная фраза. После неё обычно выясняется, что есть инструменты, но нет управления.
Миф 4. «Главное — собрать всё»
Нет.
Собрать всё — это не стратегия. Это складирование.
Если просто собрать все данные в одно место, не описать их, не назначить владельцев, не ввести правила качества, не определить сценарии использования, то получится не Data Lake, а data swamp — болото данных.
Там вроде бы всё есть, но найти ничего нельзя. А если нашёл, непонятно, можно ли этому доверять.
Миф 5. «Мы не IT-компания, нам это не нужно»
Данные нужны не только банкам, маркетплейсам и BigTech.
Производство использует данные для планирования загрузки и обслуживания оборудования. Логистика — для маршрутов, сроков, складских запасов. HR — для анализа текучести и эффективности найма. Юридические функции — для работы с договорами, рисками, претензионной практикой. Клиентский сервис — для анализа обращений и качества обслуживания.
Если компания принимает решения, обслуживает клиентов, управляет ресурсами и отвечает за результат, значит данные ей нужны.
Миф 6. «У нас и так всё работает»
Работает — пока рынок стабилен. Пока конкуренты не стали быстрее. Пока регулятор не изменил требования. Пока ключевой сотрудник с Excel-файлом не ушёл в отпуск. Пока не понадобилось внедрить AI. Пока не случился кризис.
Слабая работа с данными часто не видна в спокойное время. Она проявляется в момент изменения.
Как меняется роль управленца

Современный управленец не должен быть просто потребителем отчётов.
Он должен быть участником процесса работы с данными.
Это не значит, что он должен руками строить витрины или проектировать архитектуру. Но он должен:
- понимать, какие данные есть в зоне его ответственности;
- знать, откуда они берутся;
- понимать, как они используются;
- требовать данные как основу для решений;
- создавать культуру ответственности за качество;
- говорить с IT и аналитиками на одном языке.
Хороший управленческий вопрос сегодня звучит не так:
Почему у нас нет красивого дашборда?
А так:
Какие решения мы хотим принимать быстрее и точнее, какие данные для этого нужны, где они рождаются, кто за них отвечает и можем ли мы им доверять?
Вот это уже начало зрелого подхода.
Немного истории: почему базы данных стали такими разными

Чтобы понимать современную архитектуру данных, полезно посмотреть, как мы сюда пришли.
| Период | Что произошло | Ключевые технологии |
|---|---|---|
| 1970-е | Эдгар Кодд предложил реляционную модель: таблицы, строки, столбцы, связи | Реляционная теория, SQL |
| 1980-е | Реляционные СУБД стали коммерческим стандартом | Oracle, IBM DB2, стандартизация SQL |
| 1990-е | Интернет увеличил масштабы. Появились OLAP и хранилища данных | MySQL, PostgreSQL, DWH, OLAP |
| 2000-е | Web-scale компании упёрлись в ограничения классических СУБД | MapReduce, BigTable, Dynamo |
| 2007—2012 | NoSQL-революция: ответ на новые типы данных и горизонтальное масштабирование | MongoDB, Cassandra, Redis, CouchDB |
| 2013—2018 | Облака и managed-сервисы упростили хранение и обработку | Cloud-native DWH, Spark, Kafka, Airflow |
| 2019—2024 | Lakehouse объединил гибкость Lake и структуру Warehouse. AI породил спрос на векторные БД | Lakehouse, векторные СУБД, RAG |
Главный вывод из этой истории простой:
каждая новая волна технологий появлялась не потому, что старые технологии стали плохими, а потому что менялись задачи.
Не существует одной базы данных «на всё». Есть разные классы задач, и под них нужны разные решения.
Типы данных: не все данные одинаковые

Прежде чем говорить о базах данных и архитектурах, нужно разобраться с самими данными.
Принято выделять три больших типа:
- структурированные;
- полуструктурированные;
- неструктурированные.
Структурированные данные

Структурированные данные — это самый привычный формат.
Представьте Excel-таблицу:
- каждая строка — отдельная запись;
- каждый столбец — понятное поле;
- у каждого поля есть тип: дата, число, текст, статус, сумма.
Примеры:
- таблица заказов;
- справочник клиентов;
- бухгалтерские проводки;
- складские остатки;
- платежи;
- графики смен.
Такие данные хорошо ложатся в реляционные базы. Их удобно проверять, анализировать, агрегировать, использовать в отчётности.
Главное преимущество структурированных данных — предсказуемость.
Если поле называется order_date, понятно, что там должна быть дата заказа. Если поле называется amount, там ожидается сумма. Если поле называется status, там должен быть статус из ограниченного набора значений.
Для управленческой отчётности это фундамент.
Полуструктурированные данные

Полуструктурированные данные — это уже не строгая таблица, но ещё не полный хаос.
Обычно это JSON, XML, YAML, события, API-ответы, логи.
У них есть внутренняя структура, но она может быть гибкой. Один объект содержит одни поля, другой — другие. Вложенность может меняться. Данные могут приходить из внешнего сервиса, мобильного приложения, веб-системы, IoT-устройства.
Аналогия: если структурированные данные — это строгая анкета, где все поля обязательны, то полуструктурированные — анкета с блоками «по ситуации».
У одного клиента есть телефон и email. У другого — телефон, email, Telegram и история заказов. У третьего — только идентификатор из внешней системы.
Полуструктурированные данные очень важны для современных интеграций. Большая часть API и событийных систем работает именно так.
Неструктурированные данные

Неструктурированные данные — это тексты, письма, договоры, сканы, изображения, аудио, видео, презентации, обращения клиентов, переписки.
То есть всё то, что не укладывается в простую таблицу.
Раньше такие данные часто просто хранили как файлы. Они были важны для людей, но плохо доступны для машинной обработки.
Сегодня ситуация изменилась. С развитием машинного обучения, LLM, OCR, speech-to-text и векторного поиска неструктурированные данные стали источником огромной ценности.
Например:
- можно анализировать обращения клиентов;
- искать похожие договоры;
- выявлять типовые причины жалоб;
- строить поиск по внутренним документам;
- создавать корпоративных ассистентов;
- извлекать смысл из переписки и текстов.
Но есть важный нюанс: неструктурированные данные требуют специальных методов обработки. Обычная таблица здесь не поможет.
Источники данных: откуда всё берётся

Данные не появляются из воздуха. Они рождаются в процессах.
Есть внутренние источники:
- CRM;
- ERP;
- 1С;
- кассовые системы;
- складской учёт;
- HR-системы;
- системы документооборота;
- системы управления задачами;
- почта;
- мессенджеры;
- продукты компании;
- внутренние сервисы;
- промышленное оборудование;
- датчики и устройства.
Есть внешние источники:
- государственные реестры;
- открытые данные;
- партнёрские системы;
- поставщики;
- логистические операторы;
- платёжные сервисы;
- социальные сети;
- внешние API;
- публичные датасеты.
Есть ещё одна важная классификация: онлайн и офлайн.
Онлайн-источники дают данные почти в реальном времени: клики, события приложения, транзакции, телеметрия.
Офлайн-источники передают данные периодически: выгрузка из 1С раз в ночь, отчёт поставщика раз в неделю, Excel-файл от партнёра раз в месяц.
Для бизнеса это не техническая деталь. От типа источника зависит, насколько быстро можно принимать решения.
Если вы управляете складскими остатками, задержка в сутки может быть приемлемой. Если вы управляете антифродом в платежах, задержка в сутки превращает систему в музей.
Вопросы управленцу
- Какие решения в вашей функции требуют данных в тот же день?
- Где достаточно недельной или месячной периодичности?
- Какие источники сейчас считаются внешними, но фактически влияют на ежедневные решения?
Почему «собрать всё в одно место» сложнее, чем кажется
На уровне идеи всё выглядит просто:
- у нас есть данные в разных системах;
- давайте соберём их в одно хранилище;
- построим отчёты;
- начнём принимать решения.
В реальности начинается веселье.
Разные форматы
Одна система отдаёт таблицы. Другая — JSON. Третья — XML. Четвёртая — PDF. Пятая — архив с файлами. Шестая — поток событий.
Прежде чем данные объединять, их нужно разобрать, привести к понятному виду и описать.
Разные идентификаторы
Один и тот же клиент может иметь разные ID в CRM, ERP и бухгалтерии. Один товар может называться по-разному у склада, закупок и маркетинга.
Пока нет единой логики мастер-данных, компания не может уверенно сказать, что видит один и тот же объект.
Разные правила учёта
В одной системе сумма хранится с НДС. В другой — без НДС. Где-то дата означает дату создания заказа. Где-то — дату оплаты. Где-то — дату отгрузки.
Формально поля похожи. По смыслу — разные.
Именно здесь рождаются отчёты, которые спорят друг с другом.
Разная частота обновления
CRM обновляется постоянно. 1С выгружается ночью. Партнёр присылает файл раз в неделю. Внешний API иногда недоступен.
Если это не учитывать, аналитика будет показывать странные результаты. Не потому что система сломалась, а потому что данные живут в разных ритмах.
Права доступа и безопасность
Не все данные можно просто взять и переложить. Есть персональные данные, коммерческая тайна, регуляторные требования, внутренние политики безопасности.
Работа с данными — это не только про технологии. Это ещё и про ответственность.
ETL, ELT и CDC: как данные двигаются между системами
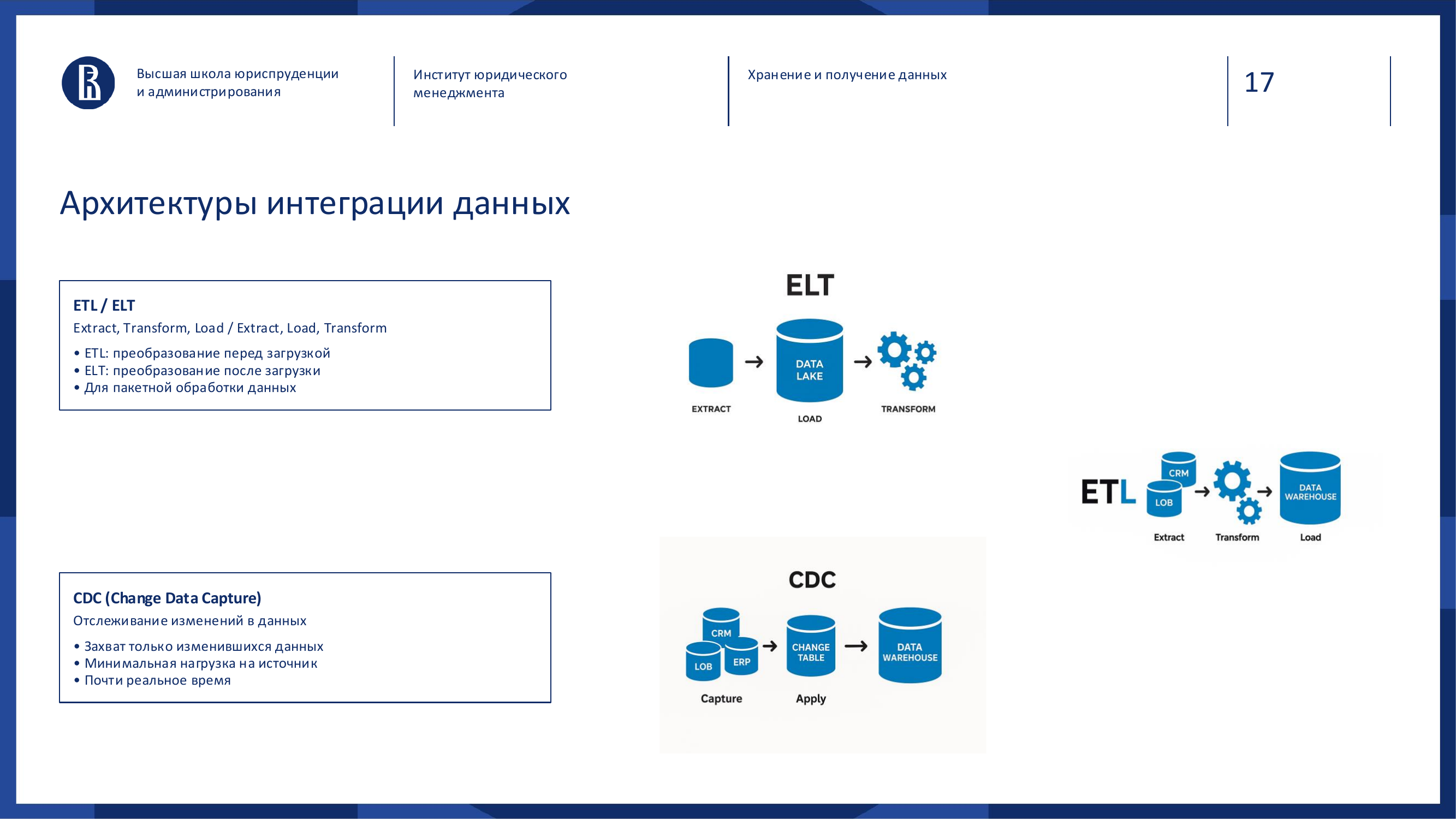
Чтобы данные из разных источников попали в хранилище, нужна интеграция.
Есть три подхода, которые руководителю стоит знать: ETL, ELT и CDC.
ETL: Extract, Transform, Load
ETL означает:
- Extract — извлечь данные;
- Transform — преобразовать;
- Load — загрузить.
То есть сначала данные забираются из источника, потом очищаются, нормализуются, приводятся к нужной структуре, и только после этого загружаются в хранилище.
Аналогия: бухгалтер сначала собирает первичные документы, проверяет их, исправляет ошибки, приводит к единому виду и только потом формирует итоговый отчёт.
Плюс ETL — контроль качества до загрузки. Минус — процесс может быть медленным и менее гибким.
ETL хорошо подходит для классической отчётности и ситуаций, где важна строгая подготовка данных.
ELT: Extract, Load, Transform
ELT меняет порядок:
- Сначала извлекаем.
- Потом загружаем как есть.
- А преобразуем уже внутри хранилища.
Аналогия: мы складываем все документы в большой архив, а потом внутри архива раскладываем, очищаем, группируем и анализируем.
ELT стал особенно популярен с развитием мощных облачных хранилищ и аналитических платформ. Они позволяют быстро загрузить много данных, а потом обрабатывать их уже внутри.
Плюс ELT — скорость и гибкость. Минус — нужно мощное и хорошо управляемое хранилище, иначе получится бардак.
CDC: Change Data Capture
CDC — это подход, при котором система отслеживает изменения в источнике и передаёт только то, что изменилось.
Не нужно каждый раз выгружать всю таблицу клиентов. Достаточно передать новые записи, изменения и удаления.
Аналогия: вы не пересчитываете весь семейный бюджет с нуля после каждой покупки. Вы просто фиксируете новое изменение.
CDC полезен, когда данные нужны почти в реальном времени и когда нельзя перегружать источник постоянными полными выгрузками.
| Подход | Что происходит сначала | Сильная сторона | Где особенно уместен |
|---|---|---|---|
| ETL | Данные очищаются до загрузки | Контроль качества | Классическая отчётность и регламентированные показатели |
| ELT | Данные загружаются как есть | Скорость и гибкость | Облачные хранилища, аналитические платформы, быстрые эксперименты |
| CDC | Передаются только изменения | Близость к реальному времени | События, транзакции, оперативная синхронизация |
Главное не в названии подхода, а в том, какой управленческий ритм он поддерживает: отчёт раз в месяц, отчёт каждое утро или реакцию почти сразу.
OLTP и OLAP: почему одной базы обычно недостаточно
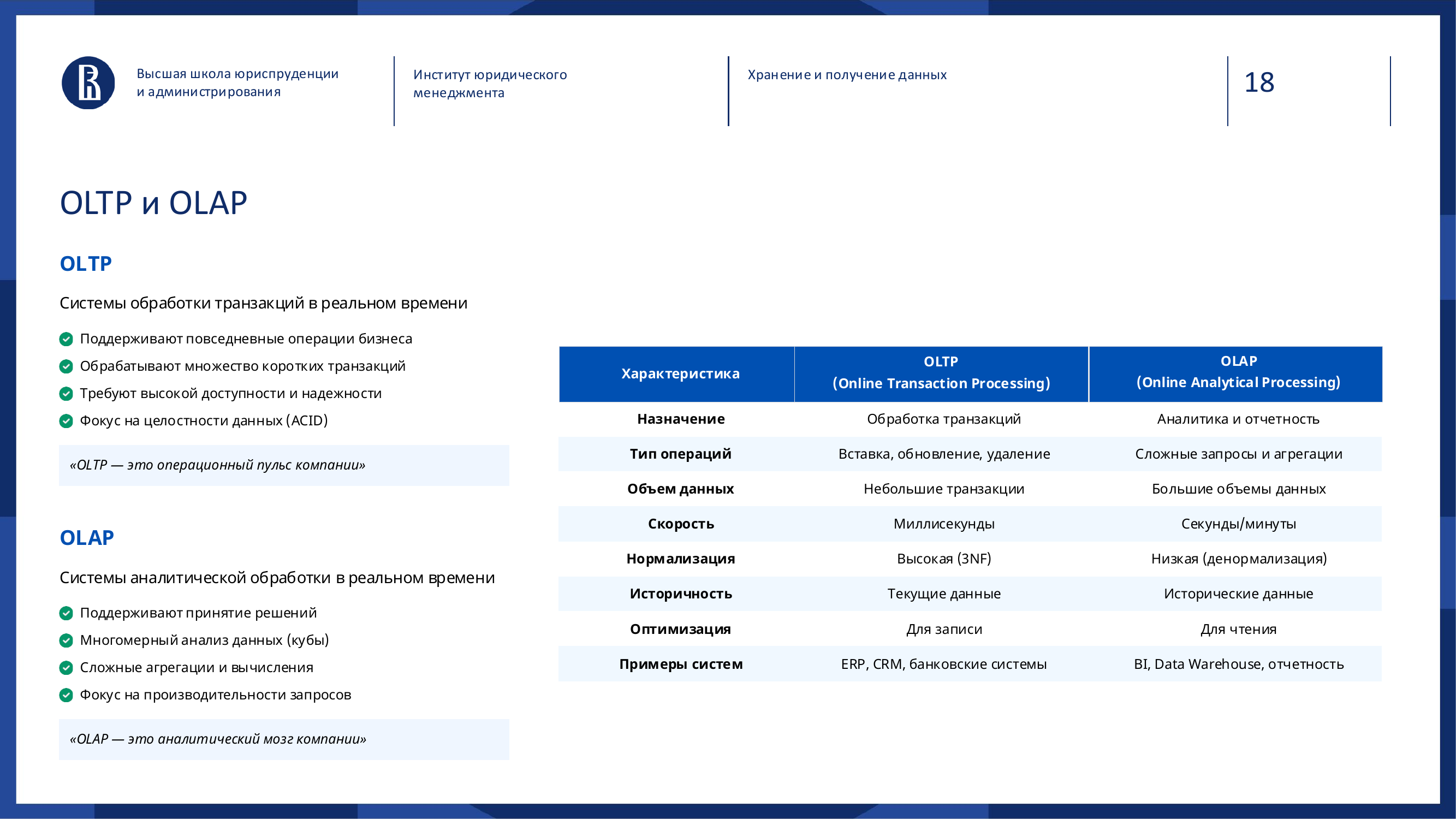
Когда люди говорят «база данных», они часто представляют универсальное место, куда можно и записывать операции, и строить отчёты, и запускать аналитику.
Но в реальности есть два разных класса задач: OLTP и OLAP.
OLTP: операционный пульс компании
OLTP — Online Transaction Processing.
Это системы, которые обслуживают ежедневные операции бизнеса:
- создать заказ;
- провести оплату;
- списать товар;
- изменить статус заявки;
- зарегистрировать клиента;
- провести транзакцию.
OLTP-системы должны быть быстрыми, точными и надёжными.
Аналогия: касса в магазине. Покупатель пробивает товар, платит, получает чек. Система должна мгновенно списать остаток, зафиксировать оплату и не ошибиться.
Если деньги списались, а заказ не создался — это проблема. Если товар продался дважды, хотя на складе был один экземпляр — это проблема. Если касса зависла из-за аналитического отчёта — это совсем плохая история.
OLTP — это про текущее состояние бизнеса.
OLAP: аналитический мозг компании
OLAP — Online Analytical Processing.
Это системы для анализа:
- как менялись продажи по месяцам;
- какие регионы растут;
- какие товары чаще возвращают;
- как ведут себя клиенты;
- какие каналы эффективнее;
- где отклонение от плана.
OLAP работает с большими объёмами исторических данных. Здесь важны агрегации, сравнения, разрезы, тренды.
Аналогия: если OLTP — это касса, то OLAP — это финансово-аналитический отдел, который изучает результаты за период и помогает принимать стратегические решения.
| Критерий | OLTP | OLAP |
|---|---|---|
| Главный вопрос | Что происходит сейчас? | Почему это произошло, как менялось и что делать дальше? |
| Тип нагрузки | Короткие операции и частые записи | Тяжёлые чтения, агрегации, исторические выборки |
| Типичный пример | Заказ, платёж, списание товара | Дашборд, прогноз, анализ продаж |
| Риск смешивания | Замедление рабочих процессов | Недоверие к отчётам и «прыгающие» цифры |
Почему нельзя просто делать аналитику в рабочей базе
Технически иногда можно. Управленчески — часто опасно.
Если аналитик запускает тяжёлый запрос к операционной базе, он может замедлить работу системы, которая обслуживает клиентов, кассы, заказы или платежи.
Кроме того, OLTP постоянно изменяется. Пока вы строите отчёт, данные могут обновиться. В итоге цифры начинают «прыгать».
И наконец, у OLTP и OLAP разные требования к структуре хранения.
- OLTP оптимизирован под запись и короткие операции.
- OLAP оптимизирован под чтение, агрегации и большие исторические выборки.
Пытаться сделать одну систему идеальной для всего — всё равно что устроить ревизию склада прямо на кассе в час пик.
Вопросы управленцу
- Какие отчёты сейчас строятся прямо по рабочим системам?
- Есть ли случаи, когда аналитика мешает операционной работе?
- Какие показатели должны быть историческими, а не только текущими?
Типы СУБД: почему у нас получился «зоопарк»

СУБД — система управления базами данных. И здесь важно понять: разные типы баз появились не ради моды, а потому что данные и задачи стали разными.
Реляционные СУБД
Это классика: PostgreSQL, MySQL, Oracle, Microsoft SQL Server.
Данные хранятся в таблицах. Есть строки, столбцы, связи, ограничения, транзакции, SQL.
Реляционная база — это как хорошо организованный архив:
- у каждого документа своё место;
- всё описано заранее;
- связи понятны;
- ошибки контролируются;
- доступ к данным предсказуем.
Реляционные СУБД хороши, когда:
- структура данных понятна заранее;
- важна целостность;
- нужны транзакции;
- есть связанные сущности: клиенты, заказы, платежи, договоры.
Для финансов, учёта, ERP, CRM, транзакционных систем SQL по-прежнему остаётся базовым и очень сильным выбором.
Документные СУБД

Документные базы хранят данные в виде документов, чаще всего JSON или BSON.
Пример: MongoDB, Couchbase, Firestore.
Они удобны, когда структура объекта может меняться. Например, карточка клиента, профиль пользователя, настройки, каталог товаров.
Аналогия: папка с анкетами. У одной анкеты пять полей, у другой десять, у третьей вложенная история взаимодействий. Не нужно заранее заставлять всех быть одинаковыми.
Документные базы дают гибкость, но хуже подходят для строгой финансовой отчётности, где нужна жёсткая схема и контроль.
Колоночные СУБД

Колоночные базы хранят данные по столбцам, а не по строкам.
Пример: ClickHouse, Amazon Redshift, Apache Druid, Apache Pinot, Vertica.
Это особенно полезно для аналитики. Если нужно посчитать сумму продаж по миллиарду строк, системе не обязательно читать всю строку целиком. Она может читать только нужный столбец — например, amount.
Аналогия: в огромной Excel-таблице вы работаете не со всем листом, а только с колонкой «Сумма».
Колоночные базы хороши для BI, отчётов, событийной аналитики, логов, мониторинга, продуктовой аналитики.
Но они не предназначены для классических транзакций уровня «создать заказ и гарантированно списать оплату».
Key-Value хранилища

Key-Value — самая простая модель: есть ключ и значение.
Пример: Redis, DynamoDB, Riak, RocksDB.
Аналогия: камера хранения. Знаете номер ячейки — быстро получили содержимое.
Такие базы хороши для кэша, сессий, токенов, счётчиков, временных данных, быстрых операций.
Но если вы хотите сложную аналитику, связи, фильтры и отчёты — это не их задача.
Графовые СУБД
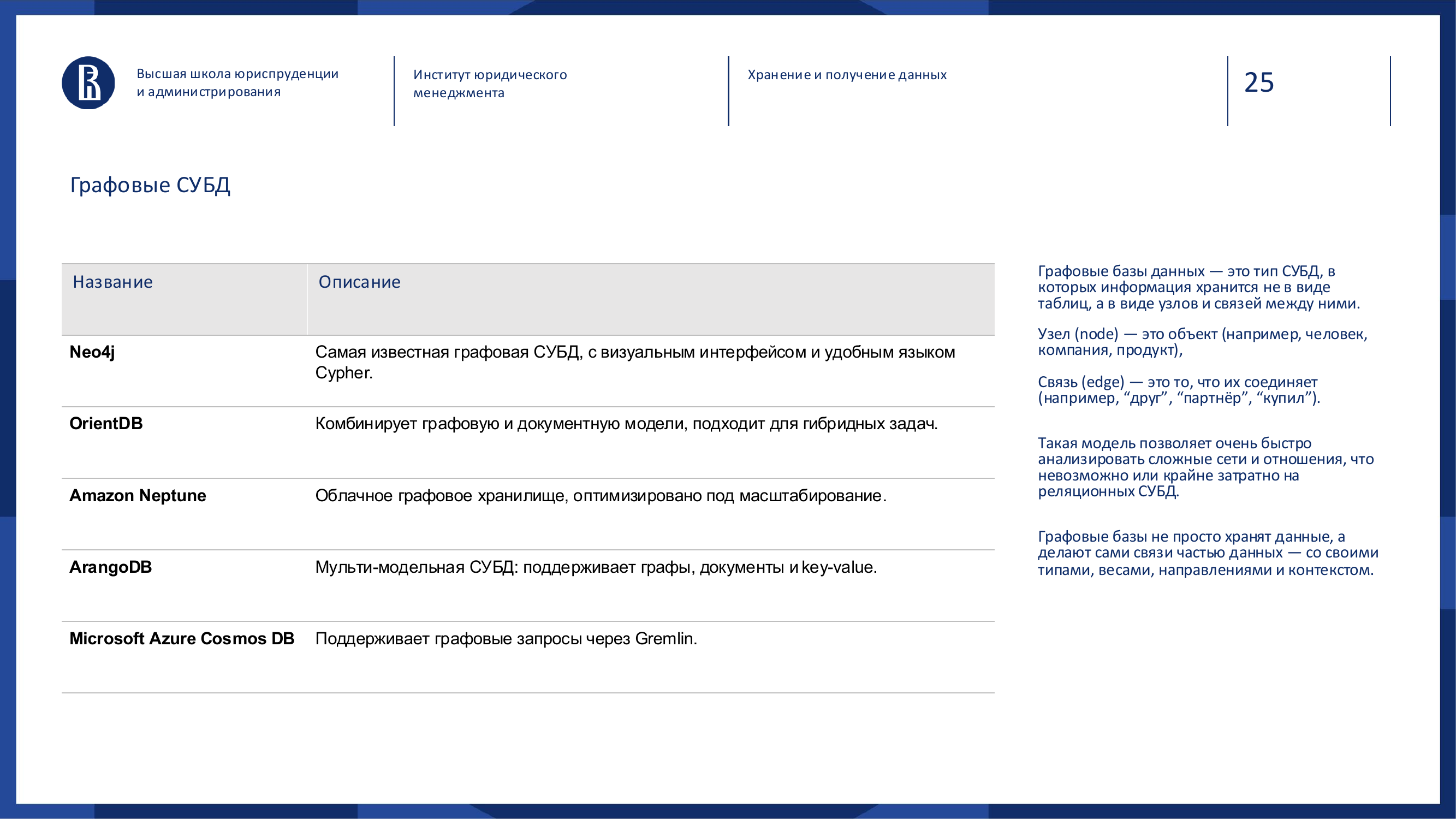
Графовые базы хранят не только объекты, но и связи между ними.
Пример: Neo4j, JanusGraph, ArangoDB, Amazon Neptune.
Узел — это объект: человек, компания, товар, счёт. Ребро — связь: купил, знает, владеет, связан, перевёл деньги, подписан.
Аналогия: карта метро. Важны не только станции, но и маршруты между ними.
Графовые базы хороши там, где связи важнее самих объектов:
- социальные сети;
- рекомендации;
- антифрод;
- цепочки владения;
- маршруты;
- зависимости;
- иерархии.
Там, где реляционная база начинает страдать от множества JOIN, графовая может быть естественным решением.
Векторные СУБД
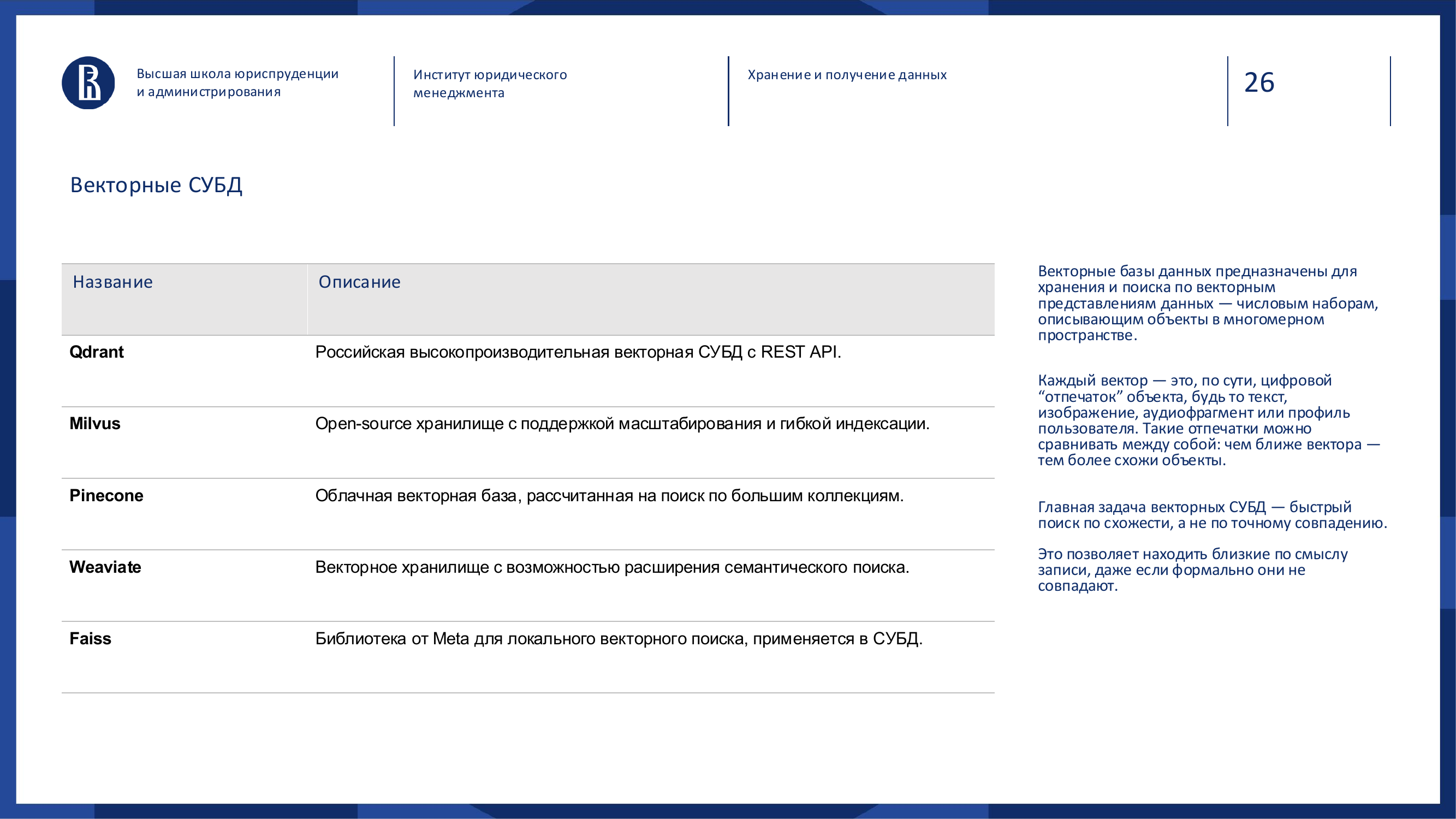
Векторные базы хранят числовые представления объектов: текстов, изображений, аудио, профилей, документов.
Пример: Qdrant, Milvus, Pinecone, Weaviate, Faiss.
Их задача — искать не точное совпадение, а похожесть.
Обычный поиск ищет слова. Векторный поиск ищет смысл.
Например, запрос «как оформить командировку» может найти документ «регламент служебных поездок», даже если в нём нет точной фразы из запроса.
Векторные базы стали особенно важны с развитием LLM и RAG-архитектур.
In-Memory СУБД

In-Memory базы работают преимущественно в оперативной памяти.
Пример: Redis, Memcached, Tarantool, SAP HANA.
Они нужны там, где важна минимальная задержка.
Аналогия: одно дело — каждый раз идти в архив за папкой. Другое — держать нужные документы прямо на столе.
Такие решения полезны для кэша, высоконагруженных сервисов, real-time сценариев, быстрых профилей клиентов, телеком- и финансовых систем.
NewSQL
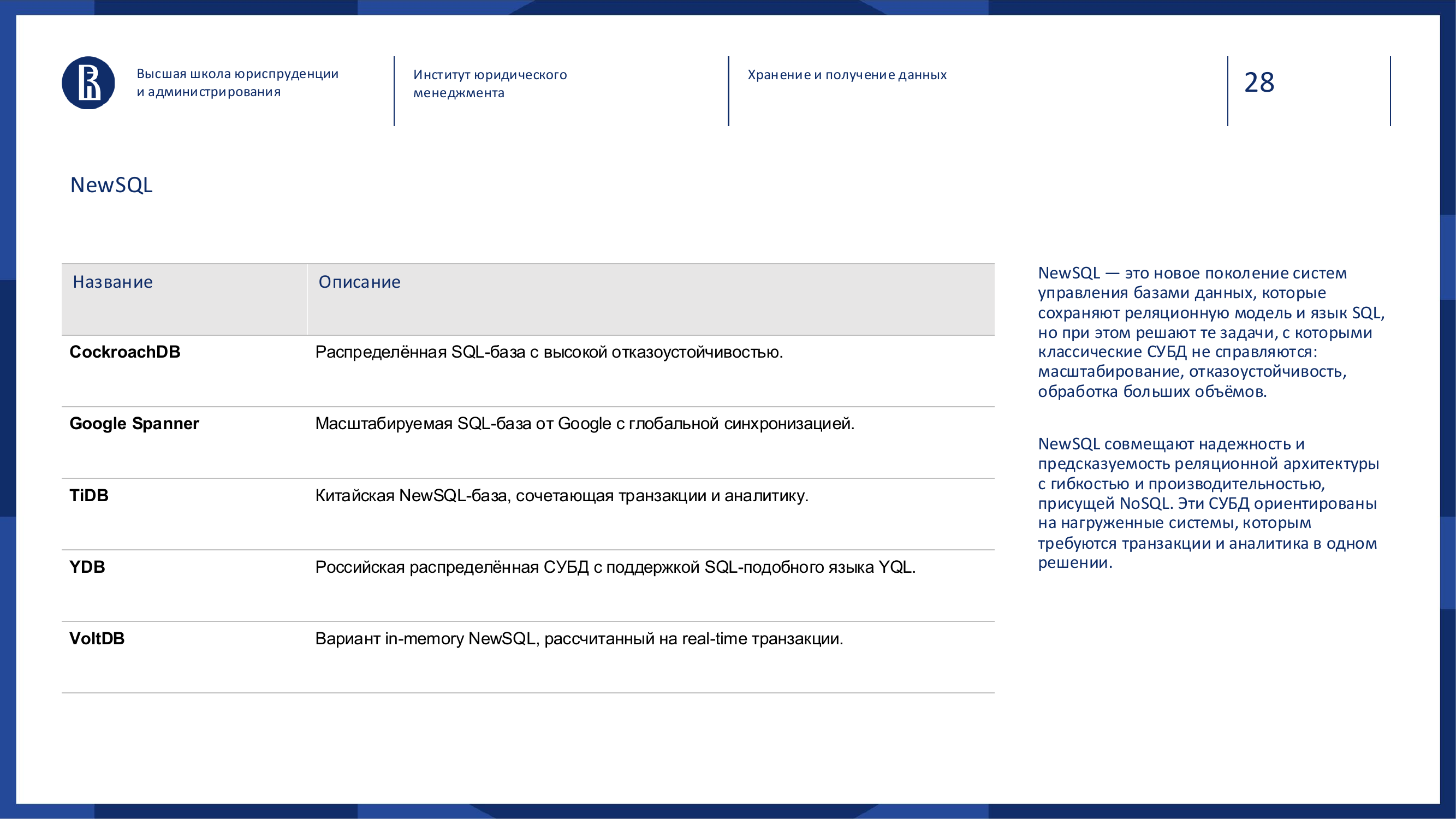
NewSQL — это попытка сохранить преимущества SQL и транзакций, но добавить масштабируемость распределённых систем.
Пример: Google Spanner, CockroachDB, TiDB, YDB.
NewSQL нужен там, где классическая SQL-база уже не справляется с масштабом, но бизнес не готов отказаться от строгих транзакций и понятной модели данных.
Это как классический автомобиль с современной начинкой: снаружи привычная логика SQL, внутри — распределённая архитектура.
Архитектуры хранения данных
Тип СУБД — это ещё не архитектура. В реальности данные компании живут в разных системах, перемещаются между ними, очищаются, агрегируются, используются разными командами.
Поэтому нужно говорить об архитектурах хранения и управления данными.
Data Warehouse: единая версия правды

Data Warehouse, или DWH, — это централизованное хранилище данных для аналитики и отчётности.
Его задача — собрать данные из разных систем, очистить, согласовать и дать бизнесу единую версию правды.
Аналогия: сеть магазинов, где у каждого магазина своя касса и свои отчёты. DWH — это центральный офис, где данные приводятся к единому виду, проверяются и становятся основой для управленческой отчётности.
Плюсы DWH:
- централизация;
- чистота данных;
- историчность;
- единые KPI;
- доверие к отчётности;
- удобная интеграция с BI.
Минусы:
- сложность запуска;
- инерционность;
- задержка обновления;
- ограниченная гибкость при новых типах данных.
DWH хорошо подходит, когда компании нужна регулярная управленческая отчётность, согласованные показатели и контроль качества данных.
Data Lake: сохраняем всё как есть

Data Lake — это архитектура, где данные хранятся в сыром виде.
Туда можно складывать таблицы, JSON, логи, изображения, документы, аудио, видео, события.
Аналогия: если DWH — это оформленный архив с каталогами, то Data Lake — огромный склад, куда можно сложить всё «про запас».
Плюсы Data Lake:
- гибкость;
- масштабируемость;
- поддержка любых форматов;
- низкая стоимость хранения;
- возможность сохранять данные до того, как понятно, как именно они пригодятся.
Минусы:
- без управления превращается в болото;
- сложно найти нужные данные;
- нет единой версии правды;
- нужна инженерная дисциплина;
- качество данных не гарантировано.
Data Lake хорош, когда данных много, они разнотипные и заранее неизвестно, какие из них понадобятся.
Data Lakehouse: попытка совместить порядок и гибкость

Lakehouse — это гибрид Data Lake и Data Warehouse.
Идея: хранить данные гибко, как в Data Lake, но добавить структуру, метаданные, транзакционность и удобство аналитики, как в DWH.
Аналогия: уже не просто склад, куда всё свалили, а современный логистический центр. Там можно хранить разные типы грузов, но есть учёт, зоны, правила, маршруты и система поиска.
Плюсы Lakehouse:
- единая платформа;
- меньше дублирования;
- поддержка BI и ML;
- работа с разными типами данных;
- возможность быстрее переходить от данных к аналитике.
Минусы:
- архитектура относительно новая;
- требует зрелой команды;
- миграция может быть сложной;
- нужна дисциплина в метаданных и процессах.
Lakehouse подходит компаниям, которые уже упёрлись в ограничения DWH или Data Lake и хотят объединить гибкость с управляемостью.
Data Mesh: данные как продукт

Data Mesh — это больше организационный подход, чем конкретная технология.
Его идея: данные должны принадлежать бизнес-доменам. Команда, которая создаёт и понимает данные, должна отвечать за их качество, документацию и доступность.
Маркетинг отвечает за маркетинговые данные. Финансы — за финансовые. Логистика — за логистические. HR — за HR-данные.
Но при этом у всех есть общие стандарты: безопасность, доступ, качество, формат, SLA.
Аналогия: рынок вместо одного огромного централизованного склада. Каждый продавец отвечает за свой товар, но правила торговли общие.
Плюсы Data Mesh:
- ответственность ближе к источнику;
- меньше узких мест в центральной команде;
- лучшее качество данных;
- масштабируемость для больших организаций.
Минусы:
- нужна высокая зрелость;
- нужна культура ответственности;
- есть риск несогласованности;
- нужны стандарты и платформа самообслуживания.
Data Mesh подходит крупным организациям, где централизованная команда данных уже не справляется с количеством доменов и запросов.
Data Fabric: единая ткань доступа

Data Fabric — это подход, при котором создаётся единый логический слой доступа к данным, даже если физически они хранятся в разных местах.
Аналогия: умный город. Районы разные, системы разные, но есть единая транспортная, информационная и управляющая инфраструктура.
Data Fabric не обязательно переносит все данные в одно место. Он связывает источники, каталоги, политики доступа, метаданные и инструменты обработки.
Плюсы:
- единый доступ;
- снижение дублирования;
- автоматизация;
- работа с распределёнными источниками;
- полезно для гибридной и мультиоблачной среды.
Минусы:
- сложность;
- высокая стоимость;
- зависимость от инструментов;
- не решает проблему качества данных сам по себе.
Data Fabric подходит компаниям, где уже много систем, хранилищ, облаков и источников, но бизнесу нужен единый доступ и управление.
Как выбирать архитектуру
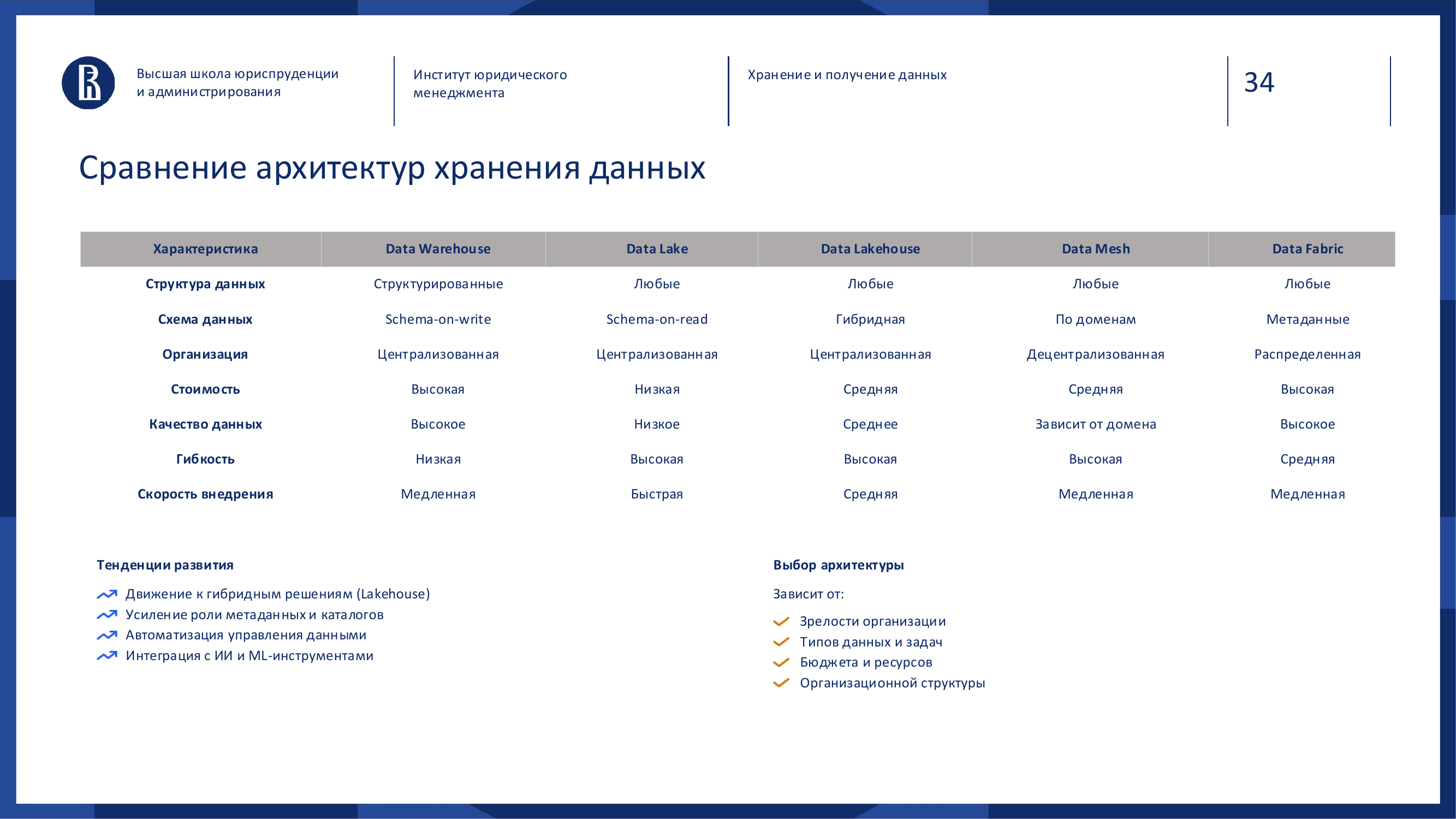
Нет лучшей архитектуры в вакууме.
| Архитектура | Когда уместна | Главный риск |
|---|---|---|
| DWH | Единая отчётность и KPI | Инерционность |
| Data Lake | Разные форматы и большие объёмы | Data swamp |
| Lakehouse | BI, ML и гибкость в одном слое | Сложность внедрения |
| Data Mesh | Много доменов и команд | Несогласованность |
| Data Fabric | Распределённые источники | Зависимость от платформы |
Коротко:
- DWH нужен, когда важны порядок и единая отчётность.
- Data Lake помогает, когда нужно сохранять много разнотипных данных.
- Lakehouse даёт баланс гибкости и аналитической управляемости.
- Data Mesh полезен, когда организация большая и ответственность нужно распределять по доменам.
- Data Fabric подходит, когда данные уже распределены, но нужен единый слой доступа.
Выбор зависит от зрелости компании, типов данных, задач, бюджета, команды и организационной структуры.
Вопросы управленцу
- Какая проблема сейчас важнее: единые KPI, скорость экспериментов, доступ к распределённым источникам или ответственность доменов?
- Есть ли команда, которая сможет поддерживать выбранную архитектуру после запуска?
- Что станет хуже, если оставить всё как есть ещё на год?
Импортозамещение СУБД: российские решения и реальность выбора
Отдельная тема, которую нельзя игнорировать в российском контексте, — импортозамещение СУБД.
За последние годы стало понятно, что зависимость от зарубежного ПО — это не только технический, но и стратегический риск. Ограничение доступа к обновлениям, поддержке, лицензиям, облачным сервисам и документации может внезапно стать бизнес-проблемой.
Особенно если речь идёт о госсекторе, финансовых организациях, критической инфраструктуре и компаниях с жёсткими требованиями к сертификации.
Важно: импортозамещение — это не «срочно заменить всё на первое отечественное». Это отдельный проект, где нужно учитывать совместимость, нагрузку, команду, стоимость миграции, поддержку, экосистему и регуляторные требования.
Зачем рассматривать российские СУБД
У российских решений есть несколько потенциальных преимуществ:
- соответствие требованиям регуляторов;
- локальная техническая поддержка;
- снижение санкционных рисков;
- учёт российской специфики;
- доступность специалистов и партнёров;
- возможность сертифицированных поставок.
Но есть и вызовы:
- функциональные ограничения;
- необходимость переобучения команды;
- стоимость миграции;
- совместимость с существующими системами;
- зрелость экосистемы;
- наличие драйверов, инструментов мониторинга, резервного копирования, репликации;
- реальная производительность под конкретной нагрузкой.
То есть выбор СУБД — это не выбор по таблице «наша / не наша». Это инженерно-управленческое решение.
SQL / реляционные СУБД
В лекционном материале были выделены следующие российские или локализованные решения в сегменте реляционных СУБД. Конкретный статус сертификации, версий и правообладателей перед реальным проектом нужно обязательно перепроверять, потому что эти данные меняются.
| Название | Происхождение | Разработчик | Сертификация в лекционном материале |
|---|---|---|---|
| Postgres Pro | форк PostgreSQL | Postgres Professional | ФСТЭК, ФСБ |
| Jatoba | форк PostgreSQL | Газинформсервис | ФСТЭК |
| Tantor | форк PostgreSQL | ТАНТОР Лабс | ФСТЭК |
| Proxima DB | форк PostgreSQL | OrionSoft | ФСТЭК |
| Ред База Данных | форк Firebird | РЕД СОФТ | ФСТЭК |
| Pangolin DB | собственная разработка | СберТех | — |
| «Квант-Гибрид» | форк PostgreSQL | КВАНТОМ | ФСТЭК |
| Arenadata Postgres | форк PostgreSQL | Arenadata | — |
| SoQoL | собственная разработка | РЕЛЭКС | ФСТЭК |
| Linter | собственная разработка | НИП ИВК | ФСТЭК, ФСБ |
Что важно заметить: значительная часть российских SQL-решений построена вокруг PostgreSQL. Это логично. PostgreSQL — зрелая open-source СУБД, вокруг которой есть сильная экспертиза, расширяемость и большая экосистема.
Для бизнеса это означает, что миграция с зарубежных enterprise-СУБД не всегда будет простой, но часто есть понятный путь: анализ совместимости, перенос схем, переписывание процедур, тестирование производительности, настройка отказоустойчивости и обучение команды.
NoSQL и NewSQL
В лекции также были выделены российские решения и решения с российскими корнями в других классах СУБД:
| Название | Тип | Происхождение / разработчик в лекционном материале |
|---|---|---|
| ClickHouse | колоночная СУБД | собственная разработка, ClickHouse Inc. / Yandex |
| Qdrant | векторная СУБД | собственная разработка, Qdrant Team |
| Tarantool | In-Memory СУБД | собственная разработка, VK / ex-Mail.ru Group |
| YDB | NewSQL | собственная разработка, Yandex |
Здесь особенно важно не смешивать разные классы решений.
ClickHouse не заменяет PostgreSQL в транзакционной системе. Qdrant не заменяет DWH. Tarantool не является универсальным архивом данных. YDB решает задачи распределённой SQL-нагрузки, но требует отдельной архитектурной оценки.
Каждая из этих систем сильна в своём классе задач.
ClickHouse — аналитика и быстрые агрегации. Qdrant — векторный поиск и AI-сценарии. Tarantool — высоконагруженные in-memory сценарии. YDB — распределённые SQL-нагрузки и масштабирование.
Как подходить к импортозамещению
Здесь нельзя начинать с вопроса: «На что заменить Oracle?»
Правильнее идти по шагам.
Сначала нужно описать текущий ландшафт:
- какие СУБД используются;
- какие системы от них зависят;
- какие нагрузки они несут;
- какие SLA требуются;
- какие есть интеграции;
- какие используются процедуры, функции, расширения;
- какие данные критичны;
- какие требования по сертификации.
Потом нужно разделить системы по критичности.
Не все базы одинаково важны. Есть экспериментальные системы, есть отчётность, есть клиентские сервисы, есть ядро бизнеса. Миграция ядра — это всегда отдельный проект с тестами, резервным планом и длительной подготовкой.
Затем нужно провести пилот.
Не презентацию поставщика, а реальный пилот на ваших данных и нагрузках.
И только после этого принимать решение.
Импортозамещение — это не разовая закупка. Это программа изменения технологического ландшафта.
Векторные базы данных и AI

Теперь перейдём к теме, которая за последние годы стала особенно актуальной: векторные базы данных и их связь с искусственным интеллектом.
Когда мы говорим о классических базах данных, обычно имеем в виду точный поиск.
Найди клиента с ID 123. Покажи заказ №456. Выбери платежи за март. Отфильтруй товары категории «электроника».
Но в реальной жизни часто нужен не точный поиск, а поиск по смыслу.
Найди похожие обращения клиентов. Покажи документы, близкие к этому вопросу. Найди товары, похожие по описанию. Подбери инструкции, которые могут помочь в этой ситуации. Найди договоры с похожими условиями.
Обычная SQL-база не очень хорошо решает такие задачи. Она не понимает, что «претензия клиента», «жалоба на доставку» и «недовольство сроками» могут быть смыслово близкими.
Для этого данные превращают в векторы.
Что такое векторизация
Векторизация — это преобразование объекта в набор чисел.
Текст, изображение, аудио, пользовательский профиль или документ превращаются в числовой «отпечаток».
Идея в том, что похожие по смыслу объекты оказываются рядом в многомерном пространстве.
Аналогия: представьте карту, где рядом расположены не города, а смыслы.
Слова «автомобиль» и «машина» будут близко. «Командировка» и «служебная поездка» — тоже близко. А «яблоко» окажется дальше, если контекст про транспорт или документы.
Векторная база хранит такие отпечатки и умеет быстро искать ближайшие.
Зачем это бизнесу
Векторные базы нужны там, где важна похожесть:
- поиск по корпоративным документам;
- умные FAQ;
- рекомендательные системы;
- анализ обращений клиентов;
- поиск похожих инцидентов;
- сопоставление товаров;
- обработка договоров;
- AI-ассистенты;
- RAG-системы.
И здесь мы подходим к RAG.
Что такое RAG
RAG — Retrieval Augmented Generation. По-русски можно сказать: генерация с дополнением через поиск.
Смысл простой: языковая модель не должна отвечать только «из головы». Она должна сначала найти релевантные фрагменты в ваших корпоративных данных, а потом использовать их как контекст для ответа.
Как это работает:
- Корпоративные документы разбиваются на фрагменты.
- Каждый фрагмент превращается в вектор.
- Векторы сохраняются в векторной базе.
- Пользователь задаёт вопрос.
- Вопрос тоже превращается в вектор.
- Векторная база ищет похожие фрагменты.
- Найденные фрагменты передаются в LLM как контекст.
- Модель генерирует ответ на основе найденных материалов.
Пример.
Сотрудник спрашивает: «Как оформить командировку в мае?»
Система не просто генерирует общий ответ. Она ищет во внутренних HR-документах, находит регламент командировок, актуальные правила, ограничения, форму заявки и только потом формирует ответ.
Именно поэтому RAG так важен для бизнеса.
Он позволяет AI работать не вообще, а с вашими знаниями, вашими документами и вашими правилами.
Почему AI без данных не работает
Многие компании хотят внедрить AI, но начинают с модели.
Какую модель выбрать? Какой чат-бот поставить? Какой интерфейс сделать? Какую LLM подключить?
Это важные вопросы, но не первые.
Первый вопрос другой:
Где ваши данные, можно ли им доверять и можно ли безопасно дать к ним доступ?
Вопросы управленцу
- Какие внутренние документы AI-система должна видеть, а какие ей видеть нельзя?
- Кто отвечает за актуальность базы знаний, на которую будет опираться RAG?
- Как вы поймёте, что ответ AI основан на правильном источнике?
Если документы устарели, база знаний не ведётся, права доступа не описаны, данные дублируются, регламенты противоречат друг другу, то AI просто ускорит хаос.
Он будет быстро и уверенно отвечать на основе плохих данных.
А это опаснее, чем медленный ручной процесс.
Что должен вынести управленец
Если собрать всю статью в несколько управленческих выводов, получится следующее.
-
Данные — это актив. Данные не должны быть побочным продуктом работы систем. У них должны быть владельцы, правила качества, жизненный цикл и понятные сценарии использования.
-
Ответственность за данные не может лежать только на IT. IT отвечает за инфраструктуру и реализацию. Но смысл данных, правила расчёта показателей, приоритеты и ценность определяет бизнес.
-
Универсальной базы данных не существует. SQL, NoSQL, NewSQL, колоночные, графовые, векторные, in-memory базы — это не модный зоопарк, а набор инструментов под разные задачи.
Плохой вопрос: «Какая база лучше?» Хороший вопрос: «Какую задачу мы решаем, какие данные у нас есть и какие требования к скорости, качеству, масштабу и согласованности?»
-
OLTP и OLAP нужно разделять по смыслу. Операционные системы фиксируют события бизнеса. Аналитические системы помогают понимать картину целиком.
Касса и аналитический отдел — разные сущности. База для заказов и база для стратегической отчётности тоже часто должны быть разными.
-
Архитектура важнее отдельного инструмента. Можно купить дорогую платформу и не получить результата. Можно начать с простых шагов и быстро улучшить качество решений.
Важно не название технологии, а то, как данные проходят путь от источника до решения.
-
Импортозамещение — это стратегический проект. Нельзя заменить СУБД по принципу «поставим аналог». Нужно анализировать нагрузку, совместимость, команду, миграцию, сертификацию, поддержку и риски.
-
AI начинается не с модели, а с данных. Векторные базы, RAG и LLM дают огромные возможности. Но только если компания понимает, где лежат её знания, насколько они актуальны и кто за них отвечает.
Вместо заключения
Мы начали с простой мысли: данные — это актив, а не инфраструктура.
Но активом они становятся не автоматически. Не потому что лежат в базе. Не потому что подключён BI. Не потому что компания купила платформу или внедрила AI.
Данные становятся активом, когда ими управляют.
Когда понятно, кто за них отвечает. Когда есть качество. Когда есть единые определения. Когда данные можно найти. Когда им можно доверять. Когда они помогают принимать решения. Когда бизнес и IT говорят на одном языке.
Руководителю не нужно знать все технические детали. Но нужно понимать карту местности.
Потому что без этой карты очень легко оказаться в ситуации, где в компании вроде бы есть всё: CRM, ERP, отчёты, BI, базы, хранилища, AI-пилоты.
А решения всё равно принимаются на догадках.
И вот этого как раз хотелось бы избежать.